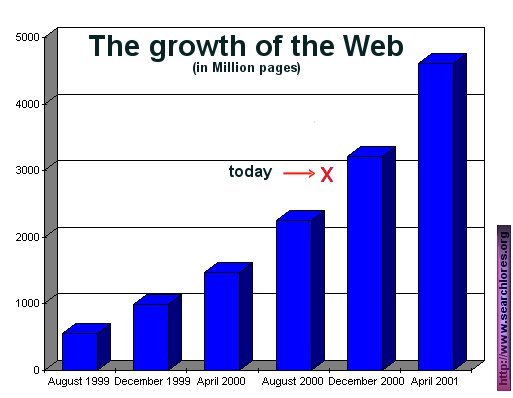
Growth
In order to search effectively you must first understand the dimension of the problem. The web is uncharted and deep. The volume of easily located
information instantly accessible to a user is so massive as to be
incomprehensible. I'll give you the data that searchers reckon to be
accurate, but be warned: nobody
really knows how big the web is. All estimates
are based on statistical methods and approaches that
have serious shortcomings and the marge
of error can be huge. What is sure is that
both dimensions and pace of growth are staggering:
In December 1997 the web had roughly 320 million pages.
In December 1999, a series of studies concluded that the web size
was about 1.000 million web pages, with about 18 trillion bytes
of textual information (one byte equates roughly one
text character), and around 200 million images: about 4
trillion bytes of data. Now (October 2000) we are approaching the
3,000 million pages (60 trillion bytes) and the
900 million images (18 trillion bytes) marks.
My graph counts only "publically available" information.
All information behind firewalls, on local intranets, and
all password-protected information, which is
available only (ahem, in theory :-) by filling out search forms, is NOT
included.
Moreover the web is
a quicksand: web pages are changed,
removed or shifted
continuously. Such changes may be minor, major, or total. According to various projects
striving to create archive snapshots of major
portions of the web, the average lifespan of a webpage is between one and
two months
3000 million pages and
the web continues to grow at an incredible pace. It
doubles in size in less than one year. Look at the curve of my graph and try to guess
which mark will be reached in december 2001.
There are many sources of information on the deep web, and each of them deserves to
be searched using specific (and various) techniques. The real first
task is figuring out where to look.
You should also consider the fact that most
information CANNOT be found using the
'classical' search engines. The "largest" search engines (google, alta, fast, northernlight)
cover (at best)
only a tiny part of the web.
Moreover they DO NOT index the most interesting parts
of the web: they index commercial over educational sites, US sites over European sites
and 'popular' sites (read sites loved by the zombies) over relatively unknown
sites. Remember also that
each 'main' search engine has different strenghts and weaknesses, and that it would be
nonsense to use always the same search engine (say altavista) to search for
any target.
Now you have the dimension of the problem. No algorithm, no computer-processing-power, no
"battery" of ultra powerful supercomputers is capable to cope with this
tide of ever-shifting exponentially rising data.
Effective searching requires new methods.
I will try to explain you some
of them.
But in order to search effectively you must first understand how the web looks like.